 William
June 10, 2025 at 2:45 PM
William
June 10, 2025 at 2:45 PM
Yeah, this paper is good. This is why I’m really interested in the LLMs playing Pokemon, because I think that is both an entertaining and highly relatable way to illustrate how LLMs fail at long-term reasoning and how far we are from truly thinking AIs. I think this paper shows pretty clearly that it doesn’t take a lot of complexity to stump the LLMs. Pokemon is a good benchmark. I think once they can solve Pokemon at or better than a 10-year-old level, we can/should freak out. It’s a much smaller hop from those reasoning skills to world domination.
The Apple researchers point to the insufficiency of current eval benchmarks as part of the problem:
We believe the lack of systematic analyses investigating these questions is due to limitations in current evaluation paradigms. Existing evaluations predominantly focus on established mathematical and coding benchmarks, which, while valuable, often suffer from data contamination issues and do not allow for controlled experimental conditions across different settings and complexities.
I think that’s true and I also believe there’s an architecture limitation. My personal theory is that current transformer-based architectures are basically just compressing information they are trained on. This is why scaling the model and data works, because they are essentially memorizing more info. The term for this is “stochastic parrot” (Bender et al., 2021).
That is very hard to prove, but I think this paper provides evidence for that theory. I think a simple explanation is that the models “collapse” at higher levels of complexity, because those problems are truly novel to them. This is also very relevant to keep in mind when requesting code changes. There’s basically a line of complexity where an LLM will never succeed.
Some of the problems reasoning models (LRMs) are trained on have multiple steps. This gives the LRMs a lift on multi-step problem benchmarks. This is the “data contamination” they are talking about - the model has already seen the problem and spits out the solution. Where these models are solving problems that are supposed to be “novel” to them, I think they are just pattern-matching reasoning steps from other seen problems that just so happen to fit. Humans do this, too, and it is a part of intelligence, but I think the LLMs are missing the “self-awareness” to assess what patterns are likely to work vs. dead ends over longer time horizons.
Here’s another snippet on this theme I found interesting and pretty damning of the ‘reasoning’ approach. I think a big change in architecture will be needed to break through this barrier:
As shown in Figures 8a and 8b, in the Tower of Hanoi environment, even when we provide the algorithm in the prompt—so that the model only needs to execute the prescribed steps—performance does not improve, and the observed collapse still occurs at roughly the same point. This is noteworthy because finding and devising a solution should require substantially more computation (e.g., for search and verification) than merely executing a given algorithm.
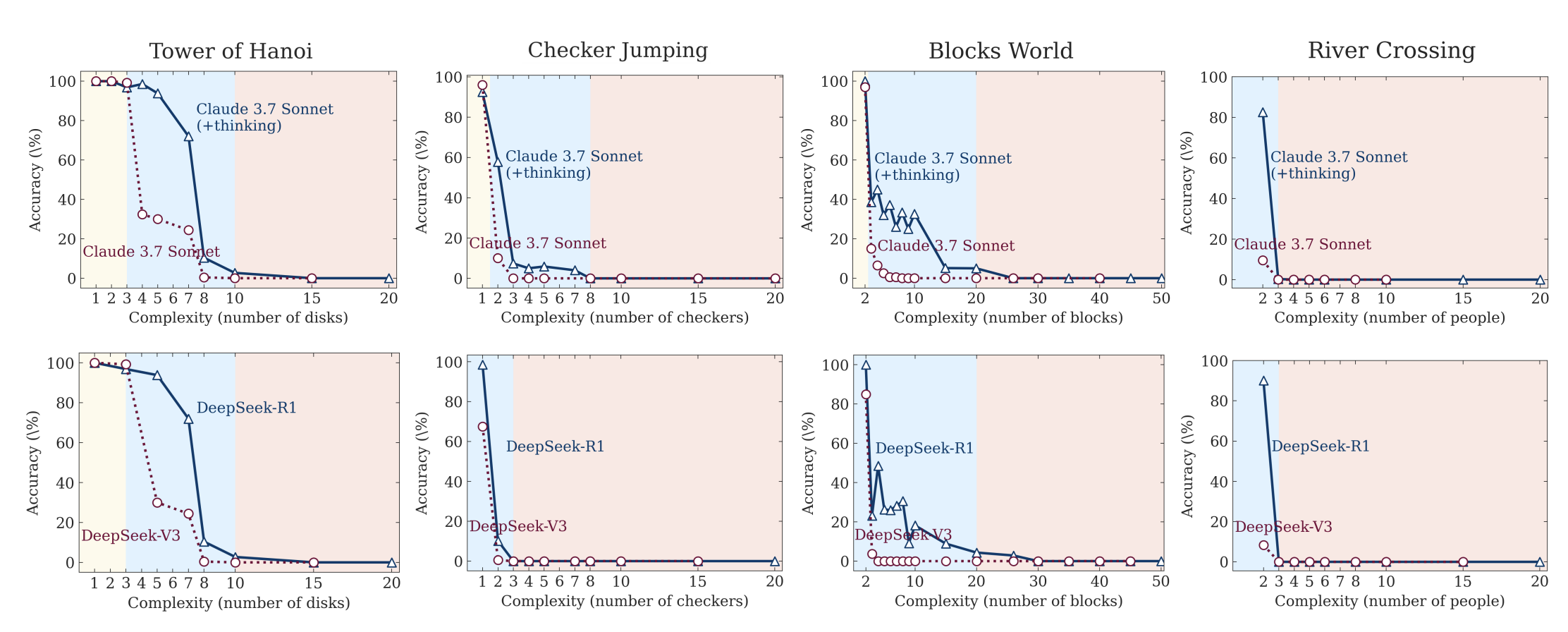 Figures 8a and 8b from “The Illusion of Thinking” - Apple ML Research. Performance collapses at the same complexity threshold even when the algorithm is provided in the prompt.
Figures 8a and 8b from “The Illusion of Thinking” - Apple ML Research. Performance collapses at the same complexity threshold even when the algorithm is provided in the prompt.
