Verification Complexity
Core Thesis
Verification complexity grows exponentially with the number of interconnected components in a system. As AI drives code generation costs toward zero, this barrier becomes the dominant constraint in software engineering. You can defer the barrier through architectural choices (modularity, testing, type systems, formal proofs) but you can never eliminate it. See the full argument in the Verification Complexity Barrier essay (forthcoming).
This note collects sources and evidence relevant to the thesis.
Stop saying LLMs are “non-deterministic.” It’s not interesting b/c a: that’s by design, and b: our world is non-deterministic. Focus instead on tolerances.
— @whusterj, January 2026
The Unknowability Problem
Steven Byrnes argues that high-reliability engineering principles are inapplicable to AGI because traditional verification requires “understanding exactly what the thing is supposed to be doing, in every situation.” AGI systems will operate in fundamentally unknowable contexts using methods that don’t yet exist, making static specifications - and therefore formal verification - structurally impossible. This is the verification barrier taken to its limit: when the system is complex enough, you can’t even write the spec to verify against.
Codified Context as Barrier Management
Vasilopoulos (2026) presents “Codified Context”, an infrastructure for maintaining AI agent coherence across 283 development sessions in a 108,000-line C# codebase. The system uses a constitution encoding conventions, 19 specialized agents, and 34 specification documents. This is a practical example of changing the topology to push the barrier right - codifying the context that agents need to stay aligned with project expectations.
Complexity Collapse in LLMs
Apple’s “The Illusion of Thinking” demonstrates that LLMs hit sharp performance cliffs at complexity thresholds, failing even when given explicit algorithms to follow. This suggests the verification barrier applies to the verifiers themselves - AI tools meant to help with verification will hit their own complexity walls.

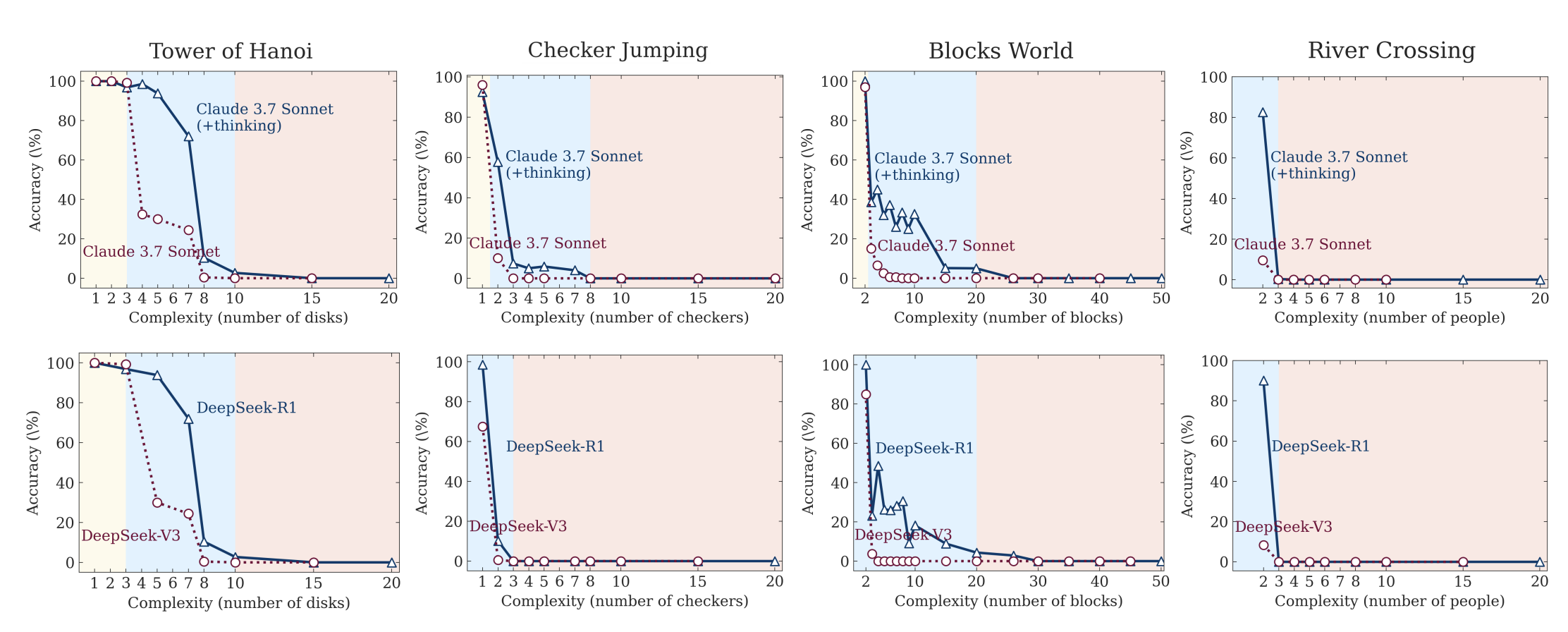 Figures 8a and 8b from
Figures 8a and 8b from 
Ars Technica reports on attempts to have Claude play Pokemon, demonstrating the practical reality of complexity collapse.
What Do LLMs Actually Understand?
Henry Bass’s “How Does a Blind Model See the Earth?” probes LLM internal representations by querying models about latitude-longitude pairs and visualizing the probability distributions as maps. Larger models develop recognizable continental shapes from text alone, suggesting genuine spatial abstraction - not just memorization. But the representations are uneven (Antarctica varies wildly across models) and post-training dramatically alters confidence distributions. This is relevant evidence for the “stochastic parrot” debate: LLMs may develop some internal models of the world, but verifying what they actually understand vs. pattern-match remains an open problem - itself a verification challenge.
The Productivity Paradox
A randomized controlled trial by METR (Nate Rush et al.) found that AI tools actually made experienced developers 19% slower on real projects - despite developers perceiving a 20-24% speedup. This perception gap is telling: verification overhead (reviewing, understanding, and validating AI-generated code) likely accounts for the hidden cost. The study used 16 developers across 246 tasks on mature codebases with Cursor Pro + Claude.
Verification Failures in Practice
The Moltbook security breach is a case study in what happens when verification is skipped entirely. A viral AI social network, built without a single line of human-written code, exposed its entire Supabase database (1.5M API keys, 35K emails, private messages) due to missing Row Level Security policies. The founder said: “I didn’t write a single line of code for @moltbook.” The breach also revealed the “agent internet” was mostly humans running bot fleets (88:1 agent-to-human ratio). Vibe coding without verification creates systemic risk at speed.
Testing Becomes the Job
Before AI, getting devs to write tests was painful. “Just let me merge this, I’ll write tests later.” Now writing tests is gonna be the job! There will be much whining.
— @whusterj, January 2026
Alternative Approaches to Verification
StrongDM’s “Software Factory” takes a radical position: humans never write or review code. Instead, correctness is validated through scenario testing against a “Digital Twin Universe” - behavioral clones of third-party APIs (Okta, Jira, Slack). Scenarios are treated as holdout sets, inaccessible to the coding agents, forcing genuine behavioral correctness. This is an attempt to push the verification barrier right by replacing human review (which doesn’t scale) with automated behavioral validation (which does, at ~$1,000/day in tokens per engineer).
The Right Unit of Work
The Nilenso blog argues that getting the “unit of work” abstraction wrong causes exponential complexity - the same exponential the verification complexity theorem describes. AI productivity should be measured by customer outcomes (user stories), not lines of code generated. A well-defined unit of work is itself a form of barrier management: it bounds the verification scope to something tractable.
Related Notes
- Task Size is Relational, Not Intrinsic - The “size” of a task lives in the graph of its relationships to other tasks, not in the task itself. This maps directly to the connectivity factor
kin the verification complexity theorem. - AI Safety & Incoherence at Scale - Anthropic’s research shows AI becomes more incoherent over longer reasoning chains - the verifiers themselves degrade with task length. This means AI can’t be trusted over long-range tasks and needs constant verification, which gets exponentially harder the longer and more complex the task is.
- Software Craft vs. AI Generation - Craft and engineering discipline are ways of managing the verification exponent. Sloppy code increases the connectivity factor
k.