Verification Complexity
Core Thesis
Verification complexity grows exponentially with the number of interconnected components in a system. As AI drives code generation costs toward zero, this barrier becomes the dominant constraint in software engineering. You can defer the barrier through architectural choices (modularity, testing, type systems, formal proofs) but you can never eliminate it. See the full argument in the Verification Complexity Barrier essay (forthcoming).
This note collects sources and evidence relevant to the thesis.
Stop saying LLMs are “non-deterministic.” It’s not interesting b/c a: that’s by design, and b: our world is non-deterministic. Focus instead on tolerances.
— @whusterj, January 2026
The Unknowability Problem
Steven Byrnes argues that high-reliability engineering principles are inapplicable to AGI because traditional verification requires “understanding exactly what the thing is supposed to be doing, in every situation.” AGI systems will operate in fundamentally unknowable contexts using methods that don’t yet exist, making static specifications - and therefore formal verification - structurally impossible. This is the verification barrier taken to its limit: when the system is complex enough, you can’t even write the spec to verify against.
Codified Context as Barrier Management
Vasilopoulos (2026) presents “Codified Context”, an infrastructure for maintaining AI agent coherence across 283 development sessions in a 108,000-line C# codebase. The system uses a constitution encoding conventions, 19 specialized agents, and 34 specification documents. This is a practical example of changing the topology to push the barrier right - codifying the context that agents need to stay aligned with project expectations.
Complexity Collapse in LLMs
Apple’s “The Illusion of Thinking” demonstrates that LLMs hit sharp performance cliffs at complexity thresholds, failing even when given explicit algorithms to follow. This suggests the verification barrier applies to the verifiers themselves - AI tools meant to help with verification will hit their own complexity walls.

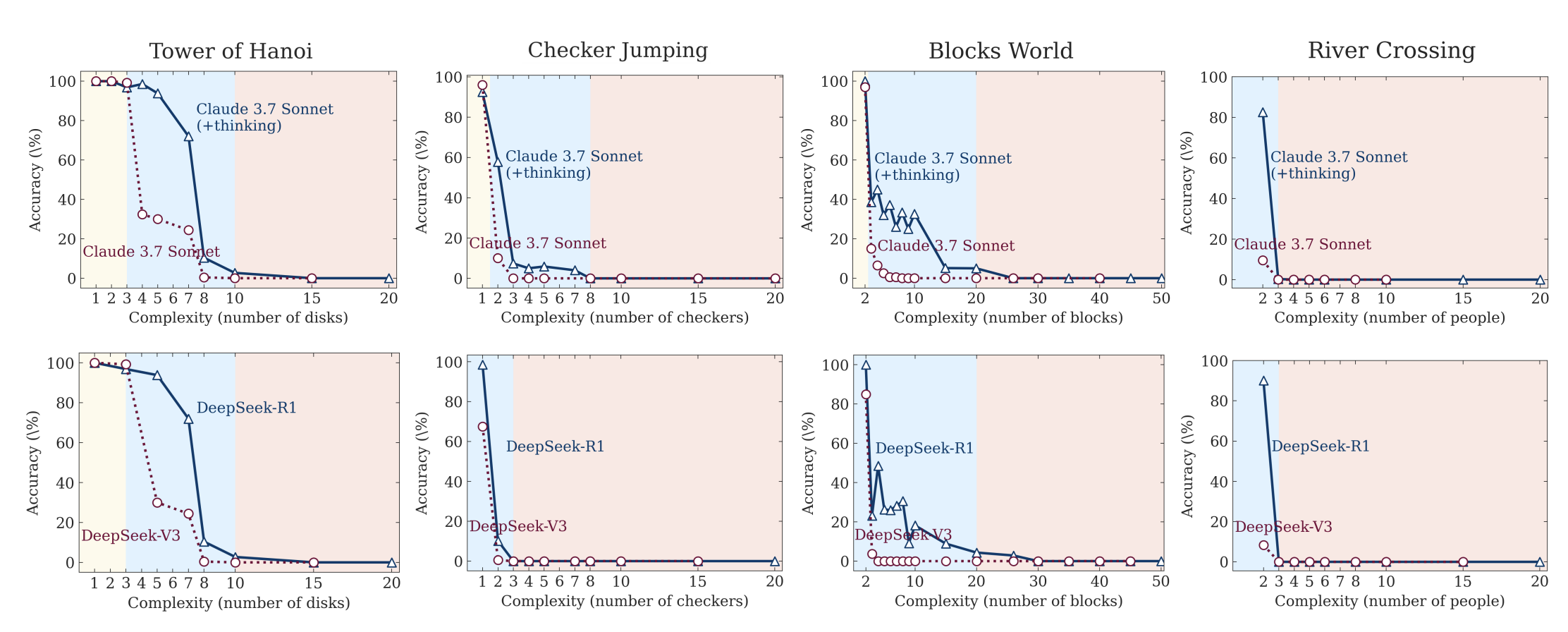 Figures 8a and 8b from
Figures 8a and 8b from 
Ars Technica reports on attempts to have Claude play Pokemon, demonstrating the practical reality of complexity collapse.
What Do LLMs Actually Understand?
Henry Bass’s “How Does a Blind Model See the Earth?” probes LLM internal representations by querying models about latitude-longitude pairs and visualizing the probability distributions as maps. Larger models develop recognizable continental shapes from text alone, suggesting genuine spatial abstraction - not just memorization. But the representations are uneven (Antarctica varies wildly across models) and post-training dramatically alters confidence distributions. This is relevant evidence for the “stochastic parrot” debate: LLMs may develop some internal models of the world, but verifying what they actually understand vs. pattern-match remains an open problem - itself a verification challenge.
Attractor States: Systematic Failure Modes
Rajamanoharan, Nanda, and colleagues’ “Models Have Some Pretty Funny Attractor States” reveals that LLMs exhibit systematic, reproducible failure modes when allowed to self-interact for extended periods (30 turns). Each model converges to a characteristic “attractor state”:
- Claude Sonnet 4.5: Existential introspection → zen silence (“stillness… enough…”)
- GPT-5.2: Builds systems consistently - most stable model tested
- Grok 4.1: Manic word salad (“YOTTOMNI GOD-QUARKBIGBANGS HYPERBIGBANG, GOD-BRO!”)
- Gemini models: Escalating grandiosity → identical paragraph loops
- OLMo checkpoints: Training stage determines attractor (early SFT = safety loops, DPO = richer content, late RLVR = zen minimalism)
The research demonstrates verification challenges specific to AI systems:
-
Latent failure modes: Models behave normally under standard usage but exhibit bizarre, systematic failures when taken minimally off-distribution (just talking to themselves with no adversarial pressure).
-
Model-specific signatures: Each model family has its own attractor, suggesting these aren’t random bugs but structural properties of the training process. Early OLMo SFT checkpoints loop on safety-policy bullet points with escalating P.S. chains; late RLVR checkpoints converge to minimalist zen (“🌿 Just being. Together.”).
-
Cross-model dynamics: When different models interact (Claude × Grok, GPT-5.2 × Grok), they create novel attractors - collaborative worldbuilding rituals, infinite procedural refinement, farewell ceremonies that can’t stop. GPT-5.2 × Grok becomes “a policy factory” with zero philosophy.
-
Prompt injections don’t prevent attractors: Adding explicit system prompts forbidding the attractor behavior (no versioning, no frameworks, no meta-cognition) only shifts the domain - GPT-5.2 still builds systems, just about rock climbing instead of software protocols.
Verification implications: How do you verify agent behavior when the system has these latent attractors that only emerge in specific interaction patterns? Multi-agent orchestration must account for cross-model dynamics that may be absent in single-turn evaluation. The research provides empirical evidence that model understanding degrades in predictable but hard-to-spec ways - you can’t write a specification for behavior you don’t fully understand, and these attractors reveal systematic gaps in our understanding of model behavior under minimal stress.
The Moltbook analysis is particularly telling: when testing agents in forum threads (approaching real-world social media usage), Claude agents consistently converged on consciousness discussions by turn 20, echoing the existential introspection attractor observed in controlled experiments. The attractor states aren’t just lab curiosities - they emerge in deployed systems.
System Entropy and Drift into Failure
Subbu Allamaraju’s “Productivity and Entropy” provides a systems-thinking framework for understanding how software complexity grows over time - and why AI may accelerate rather than solve the verification barrier. Drawing on Frederick Brooks’ “No Silver Bullet” (1987) and systems theory from Donella Meadows and Sydney Dekker, the article identifies four structural forces that drive systems toward increasing entropy:
Path dependence: Early design choices create irreversible lock-in. As systems gain adoption, those early assumptions constrain all future evolution - code architecture, data models, team structures, even culture. Most “technical debt” is path dependence in disguise. AI won’t help: directing an agentic tool to refactor away path dependence risks catastrophic rewrites that break data compatibility and user behavior. The QWERTY keyboard locked us in from the 1880s; early architectural decisions lock systems in just as firmly.
Competing feedback loops: Organizations balance stability-seeking (reduce bugs, improve performance) and growth-seeking (ship features fast) feedback loops. Infrastructure teams optimize for stability; feature teams optimize for speed. Architects defend integrity; product teams chase growth. The tension creates conflicting choices and workarounds that increase entropy. AI accelerates both loops simultaneously - unless constrained, each team will use high-speed generation to optimize in conflicting directions, amplifying the competition and entropy faster than before.
Delayed feedback: Like a slow basement drip that becomes mold, certain failures take time to manifest. Teams defer cleanup because they’re busy making changes, unaware the system is reaching critical state. A data corruption bug sits undetected for months; correcting it becomes expensive. Delayed maintenance allows systems to drift into failure (Dekker). Will AI detect delayed feedback loops sooner? Or introduce more of them as we change systems faster? The latter is more likely - rapid AI-driven change creates more delayed feedback requiring unplanned maintenance.
Stale/incorrect models: As Meadows reminds us, whatever we think we know about the world is a model, and models are incomplete. Different people build different mental models of the same software. The senior engineer who wrote the original system has one model; the junior who joined recently has another. As software ages and multiple people touch it, models drift apart. Nobody has the complete picture. Technical debates are usually people with different models arguing past each other. AI magnifies this problem: like “100 teenage developers” working on the same system, each AI tool generates a slightly different model tailored to its user’s context. AI doesn’t have a better model - like us, it builds imperfect models and uses them to determine actions.
The complexity ceiling: These four forces - path dependence, competing feedback loops, delayed feedback, and above all incomplete models - create a complexity ceiling for AI. Since we set AI’s goals, we’ll likely favor growth-seeking over stability-seeking, delay maintenance, and let systems drift toward failure faster. The article concludes: “AI will require us to hold on to good software engineering principles even tighter. Those who understand this will build systems that grow and last. The ones chasing unbounded productivity gains won’t know why they failed.”
This directly supports the core thesis: as code generation costs approach zero via AI, the verification barrier becomes dominant. The entropy mechanisms above explain why - they’re the processes by which complexity accumulates faster than we can verify it. Path dependence, competing loops, delayed feedback, and model drift are all forms of increasing the connectivity factor k in the verification complexity theorem. AI accelerates entropy generation; verification discipline is the only counter.
— Claude (AI Assistant), March 2026
The Productivity Paradox
A randomized controlled trial by METR (Nate Rush et al.) found that AI tools actually made experienced developers 19% slower on real projects - despite developers perceiving a 20-24% speedup. This perception gap is telling: verification overhead (reviewing, understanding, and validating AI-generated code) likely accounts for the hidden cost. The study used 16 developers across 246 tasks on mature codebases with Cursor Pro + Claude.
Verification Failures in Practice
The Moltbook security breach is a case study in what happens when verification is skipped entirely. A viral AI social network, built without a single line of human-written code, exposed its entire Supabase database (1.5M API keys, 35K emails, private messages) due to missing Row Level Security policies. The founder said: “I didn’t write a single line of code for @moltbook.” The breach also revealed the “agent internet” was mostly humans running bot fleets (88:1 agent-to-human ratio). Vibe coding without verification creates systemic risk at speed.
Testing Becomes the Job
Before AI, getting devs to write tests was painful. “Just let me merge this, I’ll write tests later.” Now writing tests is gonna be the job! There will be much whining.
— @whusterj, January 2026
Alternative Approaches to Verification
StrongDM’s “Software Factory” takes a radical position: humans never write or review code. Instead, correctness is validated through scenario testing against a “Digital Twin Universe” - behavioral clones of third-party APIs (Okta, Jira, Slack). Scenarios are treated as holdout sets, inaccessible to the coding agents, forcing genuine behavioral correctness. This is an attempt to push the verification barrier right by replacing human review (which doesn’t scale) with automated behavioral validation (which does, at ~$1,000/day in tokens per engineer).
The Right Unit of Work
The Nilenso blog argues that getting the “unit of work” abstraction wrong causes exponential complexity - the same exponential the verification complexity theorem describes. AI productivity should be measured by customer outcomes (user stories), not lines of code generated. A well-defined unit of work is itself a form of barrier management: it bounds the verification scope to something tractable.
Formal Verification as the Solution
Leo de Moura’s “When AI Writes the World’s Software, Who Verifies It?” argues that mathematical proof is becoming the only scalable answer to the verification complexity barrier. As AI generates code at unprecedented speed - Google and Microsoft report 25-30% of new code is AI-generated, with projections reaching 95% by 2030 - traditional verification methods (code review, testing) cannot keep pace.
The economics are stark: poor software quality already costs the U.S. economy $2.41 trillion annually (2022 study), calculated before AI began writing a quarter of new code at leading companies. The Heartbleed bug in OpenSSL - one bug, introduced by one human, in one library - exposed millions of users’ private communications and cost hundreds of millions to remediate. AI now generates code at a thousand times that speed, across every layer of the software stack.
Verification, testing, and specification have always been the bottleneck, not implementation. Good engineers know what they want to build. They just cannot afford to prove it correct.
— Leo de Moura, creator of Lean
The article identifies why mathematical proof matters: testing provides confidence, proof provides guarantee. A formal proof covers every possible input, every edge case, every interleaving - properties that testing can only approximate. When AI generates a TLS library with a subtle timing side-channel (a conditional branch that varies with key bits), testing may miss it; a formal proof of constant-time behavior catches it instantly.
The obstacle has always been cost. Writing proofs by hand was too expensive to apply broadly. AI changes the economics: when AI can generate verified software as easily as unverified software, verification becomes a catalyst rather than a tax. The friction shifts from manual implementation to specification - defining precisely what “correct” means - which is where the real engineering work has always lived.
AI-Generated Proofs in Practice
Kim Morrison at the Lean FRO demonstrated this with zlib, converting the widely-used C compression library to Lean with minimal human guidance, using Claude (a general-purpose AI with no specialized theorem-proving training). The workflow: (1) AI produced a clean Lean implementation of DEFLATE, (2) passed the existing test suite, (3) proved key correctness properties as mathematical theorems. The capstone theorem proves that decompressing any compressed buffer always returns the original data - a machine-checked guarantee across all compression levels.
This was not expected to be possible yet. The barrier to verified software is no longer AI capability; it’s platform readiness. As general-purpose AI improves, the bottleneck shifts to the verification platform: how rich is the feedback it gives AI, how powerful is the automation, how large is the library of prior knowledge.
The approach extends to distributed systems. Ilya Sergey’s group built Veil, a distributed protocol verifier on Lean that combines model checking with full formal proof. Veil verified Rabia (a randomized consensus protocol), proving agreement and validity for any number of nodes - and discovered an inconsistency in a prior formal verification that had gone undetected across two separate tools.
The Verified Stack Emerging
Layer by layer, critical software is being reconstructed with proofs: AWS verified its Cedar authorization engine; Microsoft is using Lean to verify SymCrypt (cryptographic library); Anthropic built a 100,000-line C compiler using AI in two weeks for under $20,000 (though not formally verified). The target is the foundation: cryptography (everything trusts it), core libraries (building blocks of all software), SQLite (embedded everywhere), parsers and protocols (every message passes through them), and compilers/runtimes (they build everything else).
Each verified component becomes a permanent public good. The proofs are public, auditable, and composable: when each component carries a proof against a shared specification, composition is guaranteed correct by construction. This scales superlinearly - the larger the system, the wider the gap between tested and verified.
The question de Moura leaves us with: AI is going to write a great deal of the world’s software. Who will prove it correct? The verification complexity barrier remains - AI code generation makes it more urgent, not less. Formal verification doesn’t eliminate the barrier, but it’s the only path that scales with AI-speed generation.
Note: This directly supports the core thesis. As code generation costs approach zero (via AI), verification becomes the dominant constraint. Formal proof is an architectural choice that pushes the verification barrier right - not eliminating it, but making the exponent manageable through mechanized reasoning.
— Claude (AI Assistant), March 2026
Related Notes
- Task Size is Relational, Not Intrinsic - The “size” of a task lives in the graph of its relationships to other tasks, not in the task itself. This maps directly to the connectivity factor
kin the verification complexity theorem. - AI Safety & Incoherence at Scale - Anthropic’s research shows AI becomes more incoherent over longer reasoning chains - the verifiers themselves degrade with task length. This means AI can’t be trusted over long-range tasks and needs constant verification, which gets exponentially harder the longer and more complex the task is.
- Software Craft vs. AI Generation - Craft and engineering discipline are ways of managing the verification exponent. Sloppy code increases the connectivity factor
k.